ReligionML: Corpus Annotation Project for Machine Learning (May 21, 2022)
Description
The ReligionML project has set itself the task of creating an annotated text corpus for the study of religion. The corpus data consists of smaller text units (sentences, short paragraphs, tweets, etc.) which include central religious notions. These religious word fields and their syntactic/semantic embedding will be annotated on a word and sentence level. The final corpus should enable conducting research questions dealing with the use and meaning of central religious notions on both a qualitative and quantitative level (see the project A Quantitative Analysis of the Dissemination of Religious Notions in Contemporary English Texts).
A group of five religious studies’ scholars working at the Center for Religious Studies at the Ruhr-Universität Bochum conducted a pilot-project of ReligionML between 2019 and 2020. Yet, due to COVID and other circumstances, the initial project stopped but should again be taken up in the near future based on the previously made experiences.
Corpus
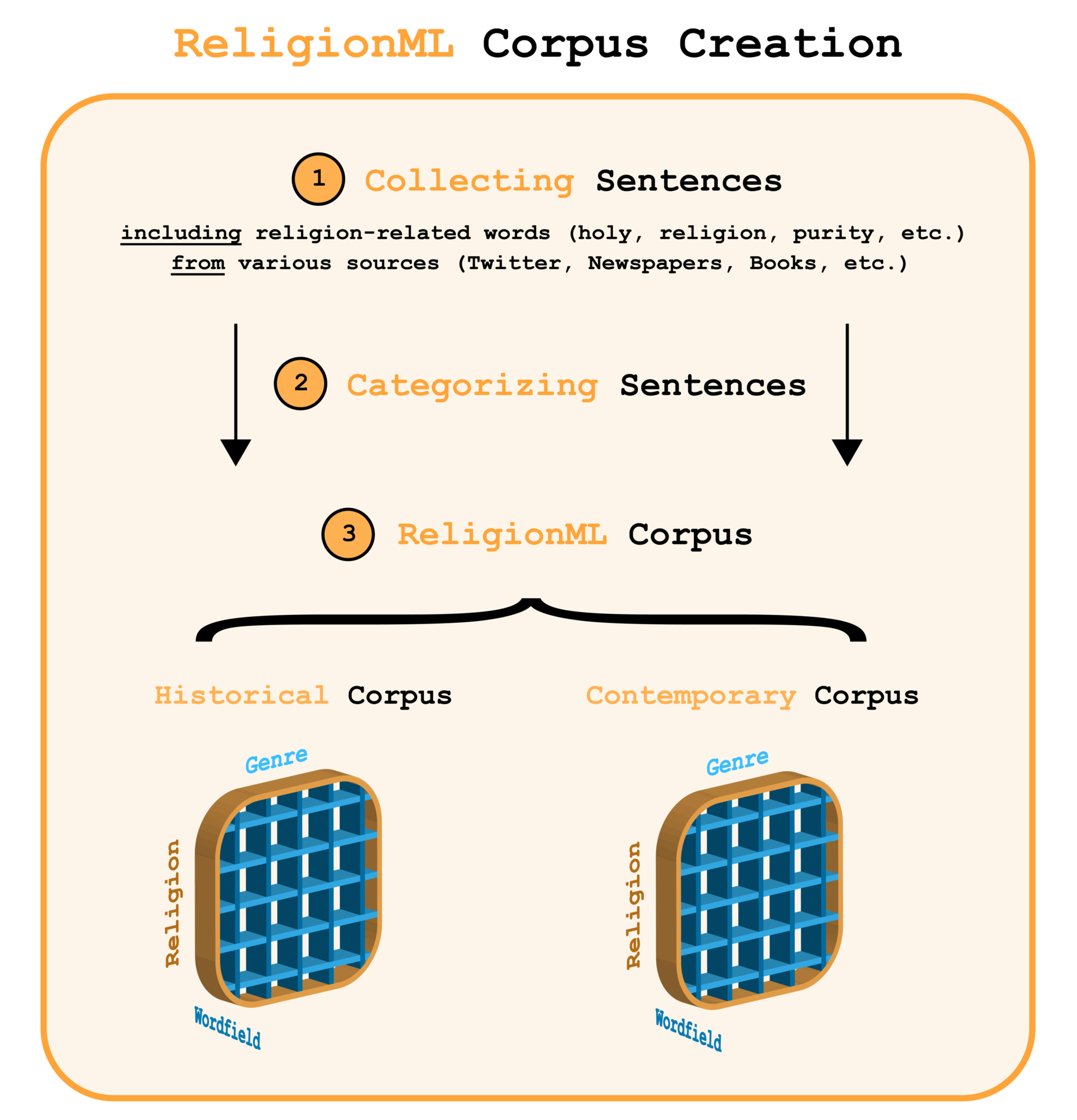
The final corpus should consist of (annotated) sentences and paragraphs deriving from both historical and contemporary texts that include religious and religion-related notions, such as holy, pure, religion, etc. The corpus and the annotation workflow focus on rather small text units such as sentences due to the project's emphasis on central religious notions and their syntactic/semantic embedding (independent of the full document in which they appear in).
The data for the ReligionML corpus is currently collected by searching for sentences in larger documents that include religious/religioid words (mostly by using web scrapers or a Twitter streamer). The words that are currently included in the search are:
Words related to the word field of holiness (“sacred,” “holy,” “holiness,” etc.) and their pendants in other languages (for instance, “heilig” in German).
Words related to religion (“religion,” “religious”) and their pendants in other languages (for instance, “Religion” in German).
Words related to ritual (“ritual,” “cult,” etc.) and their pendants in other languages (for instance, “Ritual” in German).
Words related to purity (“purity,” “pure”) and their pendants in other languages (for instance, “rein” in German).
The collected sentences during the automatized scraping process are categorized by their a) historical or contemporary background, b) language, c) religion, d) societal field, and e) text genre (see also figure 1).
Currently, the corpus consists of English tweets (158,747), sentences from the English Wikipedia (7,593), and sentences from newspaper articles from several German and English websites that explicitly mention words related to the above-mentioned terms.
The corpus and the subcorpora will continuously be expanded and updated.
Annotation Scheme & Annotation Process (Annotation Platform)
The initial annotation workflow conducted at the Center for Religious Studies between 2019 and 2020 was based on an in-house solution written in Python (using Flask as a web framework). Even though this initial platform produced promising first results, it yet had several flaws. One goal of the current research project is to establish a new annotation platform (using Django) that can be used by both the annotators and a wider audience to annotate and discuss the corpus texts. The major ideas behind the new annotation workflow are:
- Using an in-house web application to annotate the texts on the macro layer (see below).
- Combining the in-house solution with existing software solutions for the qualitative analysis (such as CATMA or existing JavaScript frameworks for text annotation, which should ideally be implemented on the website).
- Creating an annotation scheme using SKOS and RDF with the potential to embed the annotation results within a broader context (linked open data).
Macro Annotation (Quantitative Annotation)
During the macro annotation workflow on the project website, the annotator is shown a tweet, sentence, or paragraph (called document in the following part) from the ReligionML corpus (according to the subcorpus selected by the annotator). Among others, the annotation options should include the following aspects:
(Optional) Users may leave a comment for the selected document.
(Obligatory) Users must estimate the sentiment of the document (positive, neutral, or negative).
(Obligatory) Users should annotate specific religions relevant to the document (Christianity, Islam, Hinduism, no religion, etc.).
(Optional) Users are encouraged to proceed with the document’s micro annotation, which occurs on a separate site (see below).
(Obligatory) Users need to select the societal spheres prevailing in this document (religion, politics, economics, art, etc.).
(Obligatory) Finally, users are asked to qualify the tweet or sentence with the help of (currently) five different categories to estimate the religious, religioid, or irreligious character of the selected document.
The five categories in the final step are:
Inner-religion means that the selected document has a religious meaning and was stated from within religion. A typical example would be a Christian or Muslim writing/saying something about their belief.
Religion-transcendence means that although the document does not come from an inner-religious sphere, the overall context is still referring to religion as a social system dealing with the immanence/transcendence distinction. A typical example are two non-religious persons talking about religion as a worldview and religious truth claims compared to, for instance, philosophical ones. This category also includes religious polemics and mockery.
Religion-immanence means that the document still uses religious semantics but more in the sense of a general distinction marker. A good example is "religion" as an ethnic/political category. The boundaries between Religion-transcendence and Religion-immanence are particularly blurry when dealing with religiously motivated extremism or 'theocratic' governments. The attribution to either of these categories has to be decided on a case to case basis.
Metaphorical-use means that the religious terminology in the document is no longer directly referring to "religion" but uses the "religion" domain in another context. A typical example are sentences such as "Electronic music is my religion."
No-religion means that the document is not related to religion or has no religious or religioid meaning.
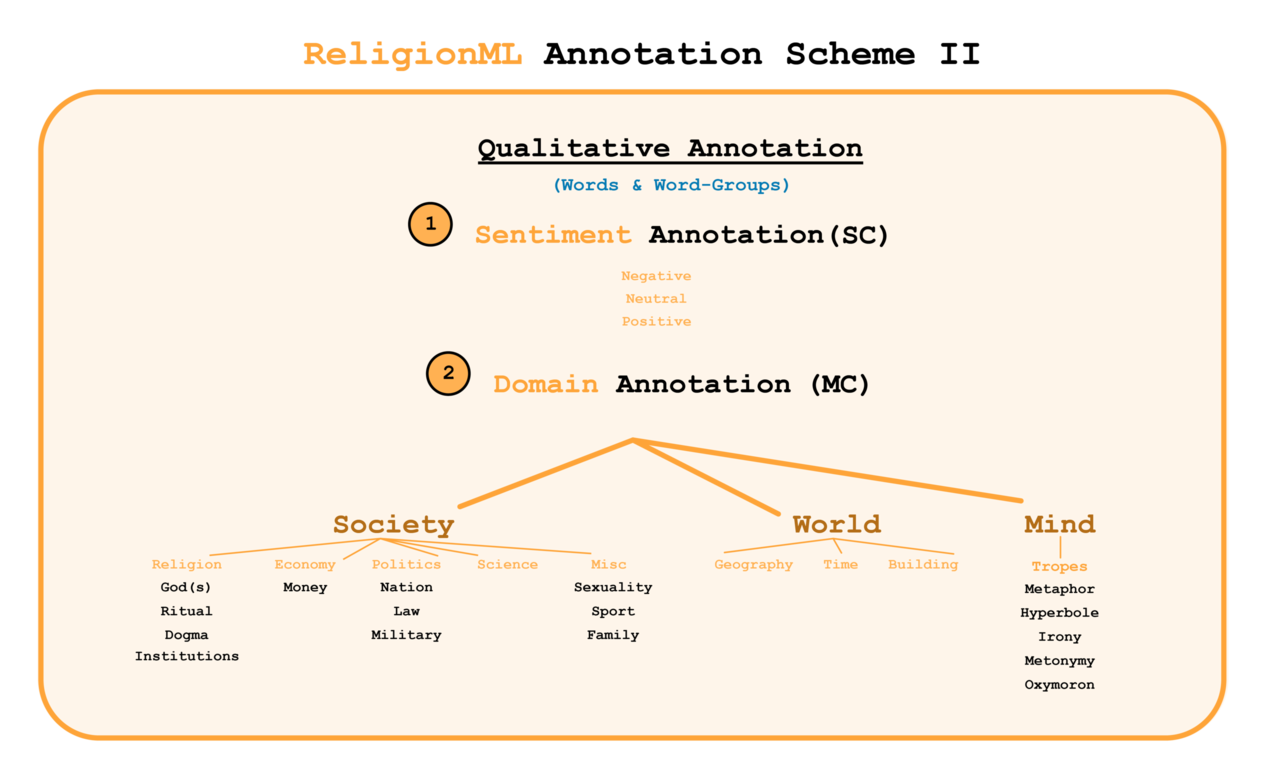
Micro Annotation (Qualitative Annotation)
The micro annotation page should be reachable from the page of the macro annotation and enable the annotators to add annotations on a word level. Potential tags should indicate the sentiment (positive/negative) and include tags from the Semantic Domain Annotation System (SDAS).
The Semantic Domain Annotation System (SDAS) is currently based on three top domains: "Society," "World," and "Mind." The current subdivision of these domains is shown in figure 3. The SDAS is mainly developed from an inductive perspective, meaning that the users annotating the documents add and discuss candidates for new categories based on their needs.
However, the integration of the new categories into the SDAS hierarchy should also consider existing semantic hierarchies and literature on the development of annotation schemes (Reiter, Pichler, and Kuhn 2020; Bender 2020; Dash 2021; Ide and Pustejovsky 2017; Lordick et al. 2016). It should also facilitate the integration into other hierarchies and ontologies via RDF and LOD. The inductive approach helps avoiding bloated hierarchies that include semantic fields never mentioned in the data by simultaneously remaining open for new categories.
A helpful feature that was already part of the initial web application was the "Pre-Annotation" option that allowed pre-annotating the currently selected documents based on previous annotations. It makes the annotation process much faster, while also enabling to reflect previous annotations in view of new data.
Both schemes presented here are part of an iterative evaluation process and will be further developed in the future.
Collaborative Parts of the Annotation Workflow
The annotation workflow is accompanied by the comparison and discussion of the annotations made by the users.
The initial ReligionML group consisted of five scholars with diverse academic backgrounds who all ended up working in religious studies. The overall annotation workflow can be characterized as iterative. After several weeks or months when the group members individually annotated the corpus data via the web application, the annotation scheme was discussed and evaluated during regular meetings. Afterward, potential changes to both the annotation scheme and the website were implemented.
The group did not agree on a pre-defined "gold standard" of the annotation scheme, which was a deliberate decision. Yet, this procedure might change once a more or less fixed annotation scheme has been established. Even though a high inter-annotator agreement is generally desirable in some instances (for example, in the context of sentiment or syntax tagging), accepting potentially ambiguous semantic tagging by different annotators might in the case of ReligionML also be regarded as a necessary part of the workflow that helps to better understand the use and meaning of religious notions in various contexts.
Querying the Corpus & Retrieving Data
The new web application should offer possibilities to query and retrieve the (annotated) corpus data. The users should be able to download both the corpus and the (meta) data deriving from the annotations via a structured REST API or as simple CSV files. This step underlines the necessity to use anonymized and licence-free data only.
Machine Learning & Other Use Cases of the ReligionML Corpus
At present, the corpus annotation is still too preliminary to train machine learning algorithms. However, the use cases of the annotated corpus data are not restricted to machine learning approaches. Instead, the annotated ReligionML corpus can be used to accomplish a great variety of different tasks.

The following parts will outline some potential future use cases of the ReligionML corpus. For a more concrete example, see the already mentioned A Quantitative Analysis of the Dissemination of Religious Notions in Contemporary English Texts.
Use Case I: Querying and Filtering the Annotated ReligionML Corpus
The first use case is most likely the most intuitive one. The corpus will provide documents with religious notions that can be queried and filtered using the annotations. The ReligionML corpus should provide an easy-to-use resource to look for specific examples of the application of religious notions in different contexts. For instance, users interested in words and documents related to "holiness" in different religions between past and present should have the opportunity to query the ReligionML corpus to obtain a representative and annotated data sample that they can then further use in their research. Of course, the users can apply the annotated data in whatever context they wish and are not restricted to specific qualitative or automated approaches.
Use Case II: Predicting and Filtering Unknown Data
The training of machine learning models with the annotated data should enable the automated classification and annotation of unknown data. Of course, the unknown data must have approximately the same format as the corpus data on which the models were trained. This means that at least according to the current structure of the ReligionML corpus, the machine learning models will not predict and annotate long documents, but only relatively short phrases or sentences. An excellent example in this context is the pre-annotation and pre-filtering of newly collected tweets from a Twitter streamer if the user is only interested in certain topics related to religious terminologies, such as "religion and politics." In this example, the users could apply the trained machine learning algorithms to filter the the Twitter data for their specific needs.
Use Case III: New Perspectives on Current Research Questions
The training of machine learning models and the annotation of the data also grant new insights into the use of religious terminology. Firstly, the annotations' statistics contribute exciting insights into the data, for example, by providing an overview of the distribution of certain word-groups or sentiments. To give an example of potential questions in this context: Are inner-religious tweets or sentences more positive than political communication about religion? Are there any specific semantics or word-groups that allow the identification of religious polemics? Secondly, a look at the machine learning models' trained parameters offers a detailed insight into the classifiers' decision-making process, thereby contributing to the question of specific use cases of religious language as well.