Data Science Introduction 2024
Data Science in den Geisteswissenschaften: Eine praxisnahe Einführung¶
Thomas Jurczyk (Dr. Eberle Zentrum für digitale Kompetenzen, Universität Tübingen)
Kontakt: thomas.jurczyk@uni-tuebingen.de
Version 0.1 (Januar 2024)
1. Einführung¶
In dieser Sitzung werde ich eine Einführung in das Thema Data Science und dessen Relevanz für die Geisteswissenschaften geben. Beginnen möchte ich mit einer kurzen Darstellung, was Data Science ist und warum Data Science auch für die Geistes- und Sozialwissenschaften relevant ist.
Ich werde dabei primär mit der Programmiersprache Python und Jupyter Notebooks arbeiten, die sich hervorragend für die Datenanalyse und deren Darstellung sowie Vermittlung eignen. Allerdings sind weder Python noch Jupyter Notebooks ein sine qua non für die Datenverarbeitung, sondern die im Folgenden zu zeigenden Schritte können auch mit anderen Programmen umgesetzt werden. Der Vorteil an einer Programmiersprache wie Python ist, dass alles an einem Ort und in einer Sprache durchgeführt werden kann.
Nach der Einführung werde ich ein im Umfang reduziertes Beispielprojekt durchführen, das einige der vorher abstrakt herausgearbeiteten Aspekte veranschaulichen soll.
2. Was ist Data Science?¶
2.1 Google Trends¶
Beginnen möchte ich mit zwei Datenvisualisierungen, die mit Google Trends erstellt wurden.
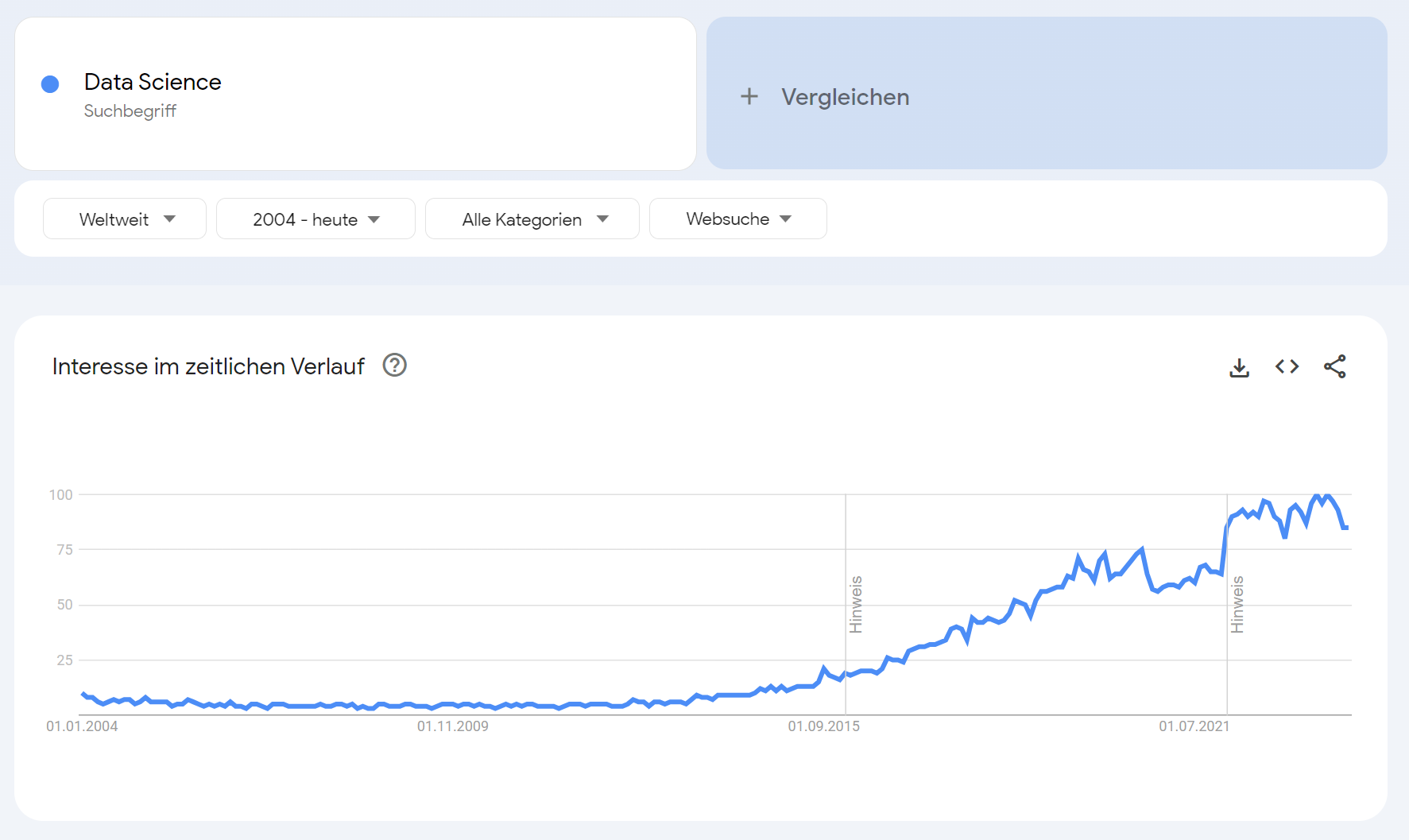
Google Trends (2004-2023). Erstellt am 03.01.2024
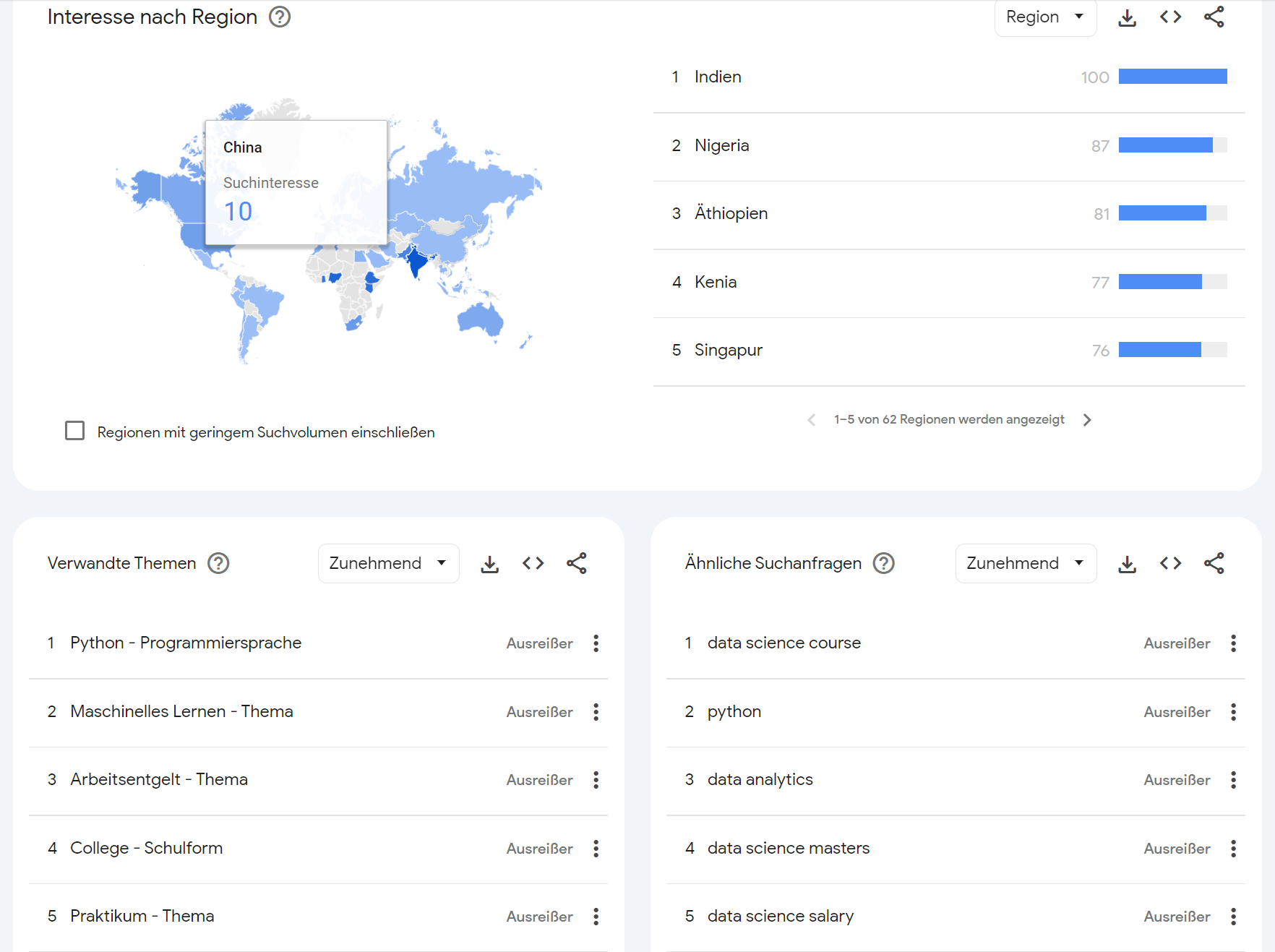
Google Trends (2004-2023). Erstellt am 03.01.2024
In den Google Trends wird deutlich, dass Data Science ...
- ... ein seit Mitte der 2010er Jahr stark an Popularität zunehmendes Feld ist.
- ... eng mit den Themen "Python", "Machinelles Lernen" und "Geld" in Verbindung gebracht wird.
- ... sich in einigen Schwellenländern besonderer Beliebtheit erfreut.
2.2 Definitionen¶
Im Weiteren wollen wir uns einige Definitionen von Data Science anschauen.
Data science is a "concept to unify statistics, data analysis, informatics, and their related methods" in order to "understand and analyse actual phenomena" with data (Hayashi 1998). It uses techniques and theories drawn from many fields within the context of mathematics, statistics, computer science, information science, and domain knowledge. (quote from this Wikipedia article, my highlights)
In diesem Eingangszitat aus der Wikipedia werden bereits viele Aspekte aufgeführt, die den Bereich Data Science charakterisieren, und es zeigt sich die Vielfalt der Bereiche, aus denen sich Data Science zusammensetzt.
Eine weitere Definition aus dem Buch "Data Science in der Praxis" (Tomy Alby, 2022) lautet wie folgt:
Data Science umfasst Prinzipien, Prozesse und Techniken für das Verständnis von Phänomenen durch die automatisierte Datenanalyse. (Provost/Fawcett in Tom Alby: "Data Science in der Praxis")
In anderen Defintionen des Begriffs "Data Science" wird dieser Bereich eng mit angewandter Statistik oder der Analyse von Big Data in Verbindung gebracht. Zusätzlich wird regelmäßig die wichtige Rolle des Maschinellen Lernens für Data Science betont.
Obwohl alle drei Bereiche in der Tat eng mit Data Science verknüpft sind, hoffe ich zeigen zu können, dass keiner von ihnen notwendig ist, um Data Science zu betreiben.
Als Arbeitsdefinition schlage ich daher vor, Data Science wie folgt zu definieren: Die Anwendung computergestützter Methoden zur Analyse von Daten, die uns dabei hilft, spezifische Forschungsfragen zu beantworten.
3. Data Science Workflow¶
Data Science Projekte können, abhängig von den zu untersuchenden Daten, sehr unterschiedlich sein. Dennoch gibt es eine Grundstruktur, die sich in vielen Projekten unabhängig von den zu analysierenden Daten regelmäßig wiederfinden lässt.
Ein Beispiel für einen wiederkehrenden Data Science Workflow findet sich im Hadley Wickham Modell (Grafik entnommen aus: Tom Alby: "Data Science in der Praxis" (Rheinwerk Verlag 2022)).
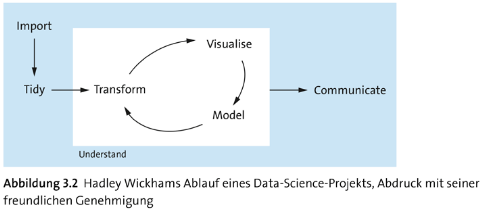
Ich würde aus meiner Erfahrung heraus sagen, dass das Hadley Wickham Modell meinem Workflow ziemlich nahe kommt, der meist wie folgt aussieht:
from tools.viz import *
gv()

Wichtig bei diesem Workflow ist es jedoch zu beachten, dass das typische Vorgehen im Projektverlauf nicht streng einem Wasserfallmodell entspricht (wie man mit Blick auf die Pfeile annehmen könnte), sondern aus Iterationen besteht, wie sie auch im Hadley Wickham Modell dargestellt sind.
Zwischenfrage: Was sind eigentlich Daten?¶
Welche Daten kennen Sie? Mit welchen Daten arbeiten Sie? Können Sie Kategorien bilden, um verschieden Datentypen zusammenzufassen?
4. Beispielprojekt: Analyse der Themen einer religionswissenchaftlichen E-Mail-Liste (Yggdrasill)¶
Im folgenden Teil möchte ich den dargestellten Data Science Workflow anhand eines Beispielprojekts veranschaulichen.
In dem hier vorzustellenden Projekt geht es um die Analyse der Beiträge, die auf der 1997 gegründeten religionswissenschaftlichen E-Mail-Liste (Yggdrasill) veröffentlicht wurden. Laut offizieller Beschreibung auf den Seiten der Universität Marburg, welche die Liste hostet, handelt es sich bei Yggdrasill um ...
[...] eine Dienstleistung der Europäischen Gesellschaft für Religionswissenschaft (European Association for the Study of Religions, EASR). Die Diskussionen bei "Yggdrasill" werden hauptsächlich auf Deutsch geführt.
Im Folgenden soll sich der Frage gewidmet werden, welche Themen im Laufe der Jahre am häufigsten besprochen wurden und ob es Themencluster gab, was einen Eindruck der Fachtradition und der sich im Laufe der Jahre verändernden Schwerpunkte im religionswissenschaftlichen Diskurs vermitteln soll.
Die Analyse konzentriert sich auf die Betreffzeilen der E-Mails (und nicht auf deren Inhalt).
4.1 Datenbeschaffung¶
In einem ersten Schritt müssen die Daten gesammelt werden. Dies ist in diesem Fall relativ leicht, da die Mails in einem Mail-Client wie Thunderbird oder Outlook gesammelt und dann exportiert werden können. In anderen Fällen kann sich die Erlangung der Daten jedoch als deutlich komplizierter herausstellen.
Neben der Frage, wie man technisch an die Daten gelangt (APIs, Web Scraping, Repositorien usw.), sind vor allem rechtliche sowie ethische Aspekte von zentraler Bedeutung. Darf ich die Daten überhaupt benutzen? Muss ich für deren Erlangung aktiv Barrieren umgehen (bspw. Bezahlschranken eines Online-Journals, dessen Artikel ich analysieren möchte)? Und selbst wenn ich rechtlich abgesichert bin, sollte ich die Daten analysieren und die Ergebnisse veröffentlichen? Müssen unter Umständen Vorkehrungen getroffen werden, um Teile der Daten zu anonymisieren oder anderweitig unkenntlich zu machen?
Diese und viele weitere Fragen lassen sich nicht einheitlich beantworten, aber sie sollten vor Projektbeginn durchdacht werden. Allgemein gilt, lieber eine Genehmigung zuviel als zu wenig einzuholen. In diesem konkreten Fall habe ich zum Beispiel die Herausgeber der Liste über mein Vorhaben informiert und versichert, dass ich die Daten nicht öffentlich verbreiten/zugänglich machen und auch von der Nennung persönlichen Daten absehen werde.
Die aus dem E-Mail Client (Thunderbird) exportierten Daten sind in einer speziellen Struktur abgespeichert, dem sogenannten MIME (Multipurpose Internet Mail Extensions) Format. Das Format sieht auf den ersten Blick relativ komplex aus. Es wurde von der Internet Engineering Task Force (IETF) in mehreren RFCs definiert (siehe u.a. RFC 2049).
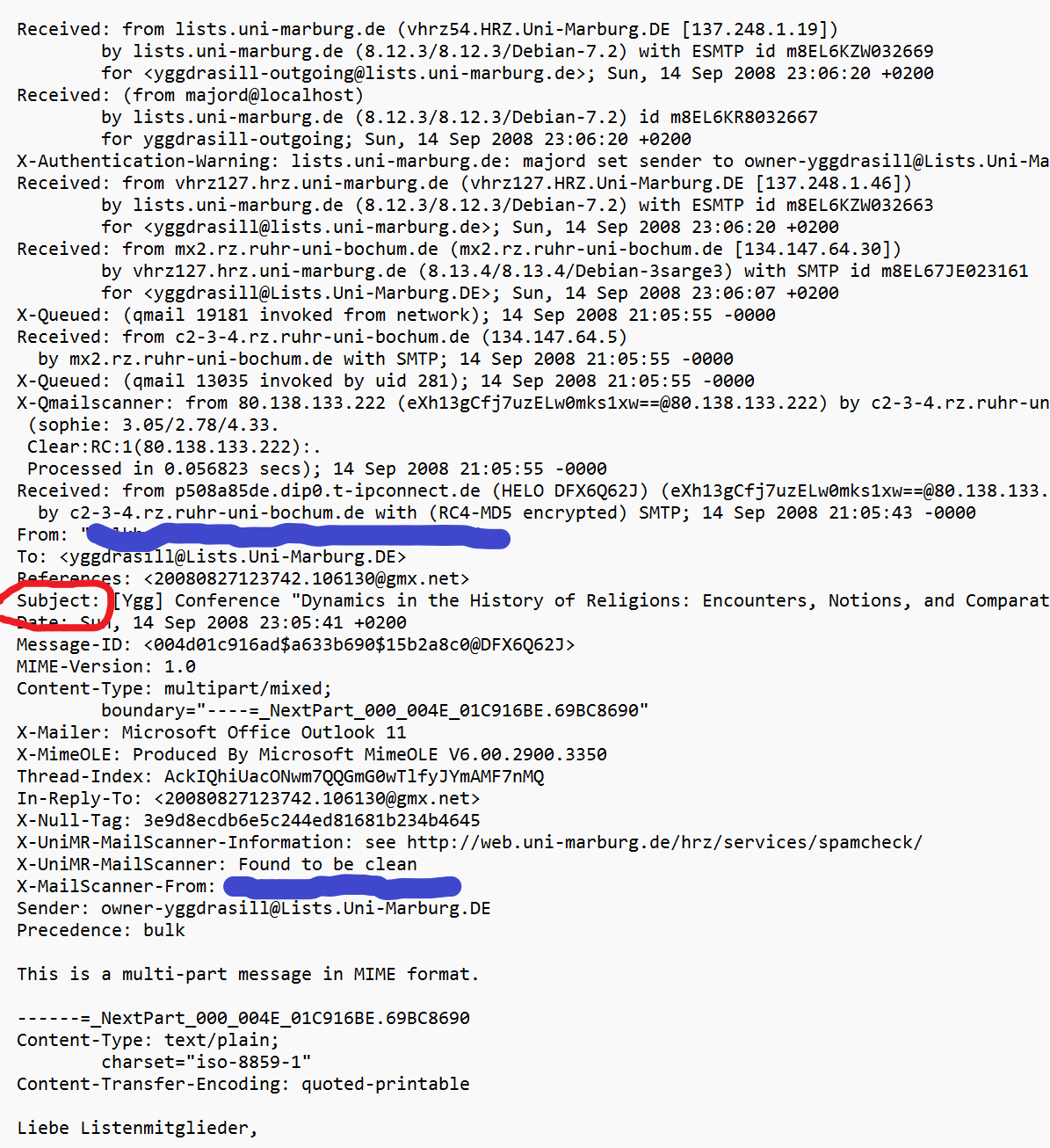
Bei einer genaueren Analyse der Struktur kann festgestellt werden, dass es neben vielen anderen Feldern auch einen Eintrag namens Subject gibt, der als Wert die zu analysierende Betreffzeile enthält.
Die Aufgabe besteht nun darin, diese Zeile möglichst automatisiert aus den einzelnen Mails auszulesen und dann in ein für die weitere Analyse geeignetes Format zu überführen.
4.2 Datentransformation¶
Das Thema der Datentransformation kann auch bei relativ einfachen Datensätzen schnell sehr komplex werden und hängt stark von der Fragestellung ab.
In diesem Beispiel sollen relevante Themen über die Jahre anhand der Betreffzeilen der E-Mails analysiert werden. Um die Analyse durchführen zu können, müssen die Daten jedoch erst in ein passendes Format gebracht werden. Dies kann händisch geschehen, was allerdings fehleranfällig ist und bei größeren Datensätzen aus Zeitgründen undurchführbar wird. Ganz abgesehen davon wird das manuelle Kopieren/Formatieren von Betreffzeilen schnell sehr eintönig, was wiederum die Fehleranfälligkeit erhöht.
Aus diese Grund solltee die Datentransformation möglichst von einem Computer durchgeführt werden. Hierzu können wir auf Programme wie OpenRefine oder eine Programmiersprache wie Python zurückgreifen. Gerade wenn regelmäßig mit sehr individuellen Datenstrukturen gearbeitet wird, bietet sich das Erlernen einer Programmiersprache an, weil sie die Flexibilität deutlich vergrößert.
Für die vorliegende Analyse sollen die Daten möglichst in eine Struktur transformiert werden, die es erlaubt, die Daten auch im Zeitverlauf zu analysieren. Hierzu bieten sich sogenannte Dictionaries oder auch Hash-Maps an. Diese bestehen aus Key/Value-Paaren, mit deren Hilfe die Daten strukturiert (abgerufen/gespeichert) werden können.
In diesem Beispiel würde dies wie folgt aussehen:
{
1997: ["Betreff 1", "Betreff 2", ...],
...
2023: ["Betreff 14289", "Betreff 14290", ...]
}
Das Dictionary nutzt die Jahre als Keys, die dann als Value eine Liste mit allen Betreffzeilen des jeweiligen Jahres referenzieren.
Damit ist die Transformation allerdings noch nicht beendet. Viele der Betreffzeilen untercheiden sich nur im Detail voneinander, was wiederum die Analyse erschwert, indem beispielsweise die folgenden drei Betreffzeilen als unterschiedliche Einträge gezählt würden, obwohl sie eigentlich auf dasselbe Thema verweisen:
[Ygg]: Diskussion im Panel DVRW-Tagung 2009
Aw: [Ygg]: Diskussion im Panel DVRW-Tagung 2009
Fwd: Re: Aw: [Ygg]: diskussion im panel DVRW-Tagung 2009
Deshalb sollen in einem weiteren Schritt die Titel mit Blick auf die Analyse möglichst vereinfacht/vereinheitlicht werden. Hierfür kommen mehrere Schritte in Betracht:
- Löschen der Tags wie
[Ygg],Fwd:,Aw:etc. - Alles in Kleinbuchstaben setzen.
- Unnötige Leerzeichen entfernen.
- Text lemmatisieren und Stopwörter (= Wörter, die nichts zentral zum Inhalt beitragen, zum Beispiel Konjunktionen) entfernen.
Diese Transformation kann unter anderem mit Hilfe von regulären Ausdrücken und mächtigen Natural Language Processing Bibliotheken wie spaCy in Python durchgeführt werden.
Nach einer entsprechenden Bearbeitung könnten die drei obigen Betreffzeilen wie folgt aussehen:
diskussion panel dvrw-tagung 2009
Das neue Format vereinfacht die Zählung gleicher/ähnlicher Betreffzeilen und konzentriert deren Inhalt auf das Wesentliche.
In einem ersten Schritt sollen die Betreffzeilen anhand mit den vorgeschlagenen Transformationen 1-3 bearbeitet und in einem entsprechenden Dictionary strukturiert werden.
Dies sieht in Python wie folgt aus (Achtung: hier wird nur das fertige Resultat geladen; für die eigentliche Transformation bitte den Code Appendix konsultieren).
import pickle
# import transformed headings
with open("subjects_1997-2023_clean.pkl", "rb") as f:
subjects_dict = pickle.load(f)
subjects_dict[1997][:10]
['kehrer ueber scientology', 'korrektion', 'tagung in england', 'beitraege', 'adresse fuer beitraege', 'mitteleuropaeische zeit', 'virtueller ausflug', 'scientology', 'noch mal scientology', 'scientology-artikel']
# create list with all subjects for later; you can ignore this right now
all_subjects = list()
for _,v in subjects_dict.items():
all_subjects.extend(v)
4.3 Explorative Datenanalyse (EDA)¶
Selbst wenn das Gefühl besteht, die eigenen Daten gut zu kennen bzw. diese sehr simpel strukturiert sind, sollte immer eine rudimentäre explorative Datenanalyse durchgeführt werden. Denn selbst wenn diese nur das bestätigt, was bereits vorher bekannt war, ist auch dies als ein Ergebnis zu werten. Außerdem kennt der Leser:in die Daten wahrscheinlich nicht so gut wie man selbst und ist daher für eine kurze Übersicht dankbar. Häufig führt die EDA aber auch zu überraschenden Ergebnissen und offenbart Eigenschaften oder sogar Probleme in den Daten, die übersehen wurden (beispielsweise unbekannte Strukturen, Outlier (Ausreißer) oder auch einfach fehlerhafte Datenpunkte).
Eine EDA enthält Zahlen aus dem Bereich der deskriptiven Statistik und Visualisierungen. Sie kann aber abhängig von der Komplexität der Daten auch weitergehende Analysen wie ein Clustering der Daten, Korrelationsanalysen und mehr beinhalten. Damit trägt die EDA gerade bei unbekannten Daten zur Hypothesenbildung bei.
Die vorliegenden Daten umfassen 14.741 Beiträge/E-Mails, was ca. 546 Beiträgen/Jahr (arithm. Mittel) entspricht (Median: 497).
Als nächstes wird die Anzahl der Beiträge pro Jahr in Form eines Linienplots visualisiert.
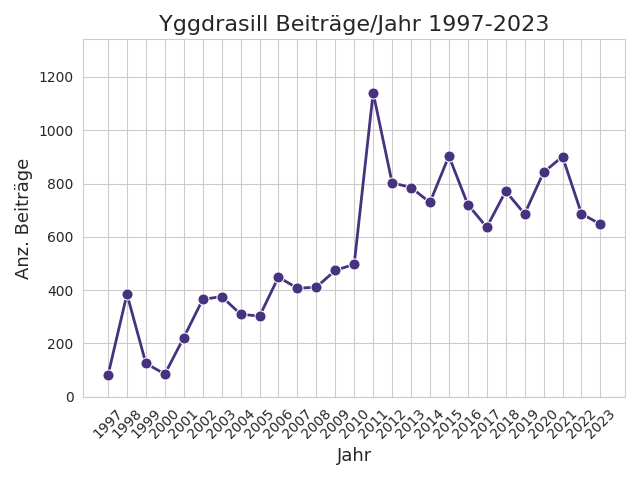
Anschließend werden die Betreffzeilen selbst untersucht, indem die Länge (= Anzahl an Zeichen) einer jeden Betreffzeile berechnet und dann deren Verteilung betrachtet wird. Hierfür wird die Längenverteilung der Betreffzeilen mit Hilfe eines Boxplot visualisiert.
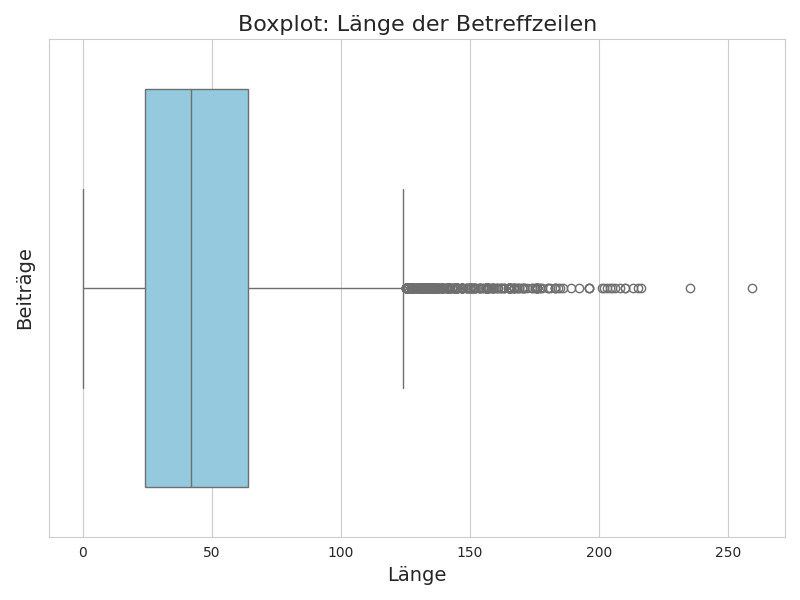
Der Durchschnitt (Median) der Betreffzeilenlänge liegt bei etwas unter 50 Zeichen, und es wird deutlich, dass einige Outlier (Ausreißer) vorliegen (zumindest nach dem Boxplot-Kriterium), die wir genauer untersucht werden sollten, da es sich hierbei auch um fehlerhafte Datenpunkte handeln könnte (sog. noise).
Im Folgenden wird die Liste aller Betreffzeilen mit mindestens 200 Zeichen dargestellt.
filter_subjects_by_length(all_subjects, 200)
array(['konferenz: historische etappen der globalisierung in christentumsgeschichtlicher perspektive, 18.\x9620. februar 2010 (fünfte internationale münchen-freising konferenz zur außereuropäischen christentumsgeschichte)',
'"discursive formation, ethnographic encounter, photographic evidence: the centenary of durkheim\'s basic forms of religious life and the anthropological study of australian aboriginal religion in his time',
'5th international kraków study of religions symposium: understanding and explanation in the study of religions, in memory of w. burkert (1931-2015), jagiellonian university in kraków, 7th-9th november 2016',
"ii congresso intern. studi ermeneutici su simbolo, mito e 'modernità dell’antico' nella letteratura italiana e nelle arti dal rinascimento ai giorni nostri, milano, università cattolica, 19-20 dic. 2016",
"p. santangelo, l' uomo fra cosmo e società. il neoconfucianesimo e un millennio di storia cinese (= man between cosmos and society: neo-confucianism and a millennium of chinese history), milano-udine 2016",
'call for papers iii intern. conf. on hermeneutics of symbol, myth and modernity of antiquity in italian literature and the arts from the renaissance up to the present day milan, università cattolica, 15-16 dec. 2017',
'intern. conf. on hermeneutics of symbol, myth and ‘modernity of antiquity’ in italian literature and arts from the renaissance to the present day, milan, università cattolica del sacro cuore, 19-20, dec., 2016)',
'[tonan] panel proposal contrasting religious multiple identitities: efforts to mark ...., congress of european society of history of religions - bern june 2018. corrige: association for the study of religions',
'cfp: globale, nationale und lokale dynamiken religiöser pluralität und ihre regulierung (sektionsveranstaltung der sektion religionssoziologie beim 39. kongress der deutschen gesellschaft für soziologie in göttingen)',
'call for papers: mothering(s) and religions: normative perspectives and individual appropriations. a cross-cultural and interdisciplinary approach from antiquity to the present, deadline dec. 21, 2018.',
'einladung zum workshop „kommunikation mit dem jenseits: von der antiken literatur bis zu modernen kinder- und jugendliteratur / communication with the underworld: from ancient literature to modern children’s and young adult literature”',
'workshop an der humboldt-universität zu berlin: kommunikation mit dem jenseits: von der antiken literatur bis zur modernen kinder- und jugendliteratur / communication with the underworld: from ancient literature to modern children’s and young adult literature',
'assistenzprofessur für religion und öffentlichkeit (religion and the public) am zentrum für religion, wirtschaft und politik (zrwp) für sechs jahre (ohne tenure track), theologische fakultät der universität zürich',
'call for papers: religion in modern education: conflict, policy and practices. hosted by the australian national university (anu), canberra, australia, 13-15 april 2023 - abstract deadline: 14 february 2023'],
dtype='<U259')
Wie es aussieht, handelt es sich auch bei den längeren Betreffzeilen um valide Einträge, weshalb diese beibehalten werden.
4. Analyse¶
4.1 Häufigste Themen¶
Zuerst sollen die jahresübergreifend häufigsten Themen aufgelistet und analysiert werden.
show_most_frequent_topics(all_subjects)
| Betreff | Anzahl | |
|---|---|---|
| 0 | heute vor 120 jahren ... | 142 |
| 1 | diskriminierung von religionswissenschaftlerinnen? - vorschlag | 101 |
| 2 | geschichte der religionswissenschaft | 83 |
| 3 | easr code of conduct | 70 |
| 4 | religionswissenschaft | 68 |
| 5 | stellenausschreibung | 65 |
| 6 | fachverständnis der religionswissenschaft | 64 |
| 7 | neuerscheinung | 59 |
| 8 | cfp reminder: rewiring the house of god / ifaith (authors' workshop) | 55 |
| 9 | zum begriff "whiteness" am beispiel von ekemini uwan | 53 |
Unter den häufigsten Themen finden sich vor allem solche, die sich mit der Fachtradition der Religionswissenschaft befassen. Auch das Thema Diskriminierung spielt eine wichtige Rolle (neben auf Mailinglisten erwartbaren Themen wie Neuerscheinungen und Stellenausschreibungen).
4.2 Themenverteilung¶
Der nächste Plot enthält ein interaktives Element, indem nach ausgesuchten Begriffen und deren Häufigkeit pro Jahr gesucht werden kann. Zeitgleich werden auch die häufigsten Betreffzeilen angezeigt, die die gesuchten Begriffe beinhalten.
SUCHWÖRTER = ["islam", "muslim"]
plot_topics_per_year(subjects_dict, SUCHWÖRTER)

[('islam bei wikipedia', 18), ('gedanken zur verantwortung der religionswissenschaft/islamwissenschaft', 16), ('aufruf islamischer gelehrter an den is', 12), ('neue schärfe in islamdebatte,drohungengegen einen kollegen (prof. rohe, nürnberg)', 7), ('ausschreibung juniorprofessuren für islamische theologie, tübingen', 7)]
4.3 Bag-of-Words Analyse (BoW)¶
In diesem Teil der Analyse wird die Häufigkeit von Wörtern aus allen Betreffzeilen gezählt (sog. bag-of-words). Der Ansatz ist sehr simpel, kann aber trotzdem einen guten ersten Eindruck dessen vermitteln, worum es in einem Text bzw. einer Textsammlung geht. Zur Veranschaulichung dienen die folgenden zwei Sätze:
(1) Ich mag Bananen. (2) Du mochtest Birnen.
Das Bag-of-Words sieht dann einfach wie folgt aus:
BoW: {"Ich": 1, "mag": 1, "Bananen": 1, "Du": 1, "mochtest": 1, "Birnen": 1}
An dieser Stelle wird deutlich, warum eine Lemmatisierung (oder auch Stemming) bei semantischen Fragestellungen sinnvoll sein kann. Denn in beiden Sätzen kommt eine Form des Wortes "mögen" vor, allerdings wird dies im BoW des nicht-lemmatisierten Textes nicht deutlich, weil hier konsequenterweise zwei unterschiedliche Wörter (types) registriert werden, nämlich "mag" und "mochtest".
Das BoW einer lemmatisierten Version der Texte sieht wie folgt aus:
(1) Ich mögen Banane (2) Du mögen Birne
BoW: {"Ich": 1, "Du": 1, "mögen": 2, "Banane": 1, "Birne": 1}
Jetzt wird deutlich, dass das Wortfeld rund um "mögen" eindeutig der häufigste Begriff in der zugegeben kleinen Textsammlung ist, was einen zufriedenstellenden Ersteindruck von deren Inhalt vermittelt.
Entsprechend wird an dieser Stelle mit einer lemmatisierten Version der Betreffzeilen weitergarbeitet (für die Details siehe den Code Appendix).
with open("subjects_lemmatized.pkl", "rb") as f:
lemmatized_subjects = pickle.load(f)
lemmatized_subjects = [sub for sub in lemmatized_subjects if sub !=""]
bow(lemmatized_subjects, top=30)
{'Religionswissenschaft': 1301,
'Ausschreibung': 321,
'Stellenausschreibung': 319,
'Neuerscheinung': 234,
'religionswissenschaftlich': 186,
'Einladung': 181,
'Universität': 162,
'Deutschland': 149,
'Religionswissenschaftlerinn': 139,
'Geschichte': 138,
'Marburg': 117,
'nochmals': 111,
'Hinweis': 107,
'Vorschlag': 106,
'suchen': 103,
'Religionswissenschaftler': 88,
'Nachtrag': 84,
'interreligiös': 82,
'Leipzig': 80,
'Erfurt': 77,
'Heidelberg': 76,
'Berlin': 74,
'Vortrag': 72,
'Fachverständnis': 72,
'Schweiz': 67,
'Frau': 65,
'Begriff': 64,
'Verantwortung': 64,
'islamisch': 62,
'Konferenz': 60}
Unter den häufigsten Wörtern finden sich viele erwartbare Begriffe wie "Religionswissenschaft", "Religionswissenschaftler" etc. Es wird außerdem deutlich, dass es häufig um Stellenausschreibungen, Neuerscheinungen und Einladungen zu Veranstaltungen geht, was für eine Mailingliste nicht untyisch ist. Spannenderweise tauchen aber auch Begriffe wie "Fachverständnis" und "interreligiös" auf, die darauf hindeuten, dass es auf der Liste auch darum geht, das eigene Fach zu reflektieren und zu diskutieren.
4.4 Themen-Cluster¶
Im abschließenden Schritt sollen die Betreffzeilen auf mögliche thematische Cluster hin untersucht werden. Dazu werden zwei fortgeschrittene Techniken verwenden: Eine vereinfachte Version von Doc2Vec mit spaCy und umap sowie HDBSCAN für das eigentliche Clustering.
An dieser Stelle soll es nicht darum gehen, wie die drei Methoden im Detail funktionieren, es sollen aber zumindest deren grundsätzliche Funktionsweise erläutert werden.
Doc2Vec:
Damit der Computer Texte miteinander vergleichen, also mit diesen rechnen kann, müssen Texte zuerst numerisiert bzw. vektorisiert werden. Hierfür existieren unterschiedliche Verfahren, zum Beispiel Tf-idf Vektorisierung oder Word2Vec bzw. das bereits genannte Doc2Vec. Im Prinzip geht es darum, einen Text (oder ein Wort) in einen Vektor aus Zahlen zu transformieren, um dann Rechenoperationen aus der linearen Algebra anwenden zu können (bspw. Kosinus-Ähnlichkeit oder Distanzmetriken wie die euklidische Distanz).</br>
Beispiel:
(1) Dies ist ein Satz. --> [0.5, 0.3, 1.5]
(2) Dies ist noch ein Satz mit mehr Wörtern. --> [0.3, 0.5, 1.2]
(3) Bochum ist die schönste Stadt der Welt. --> [10.3, 5.2, 1.2]
Wenn wir Satz (1) auf Basis der Vektoren zuerst mit Satz (2) und dann mit Satz (3) unter Verwendung der euklidischen Distanz vergleichen, sehen wir, dass der Abstand zwischen (1) und (3) deutlich größer ist als zwischen (1) und (2):
$d(1, 2) = \sqrt{(0.5 - 0.3)^2 + (0.3 - 0.5)^2 + (1.5 - 1.2)^2}=0.412$
$d(1, 3) = \sqrt{(0.5 - 10.3)^2 + (0.3 - 5.2)^2 + (1.5 - 1.2)^2}=10.96$
Mit Word2Vec können Vektoren für einzelne Wörter generiert werden, die es ermöglichen, dass ein Vergleich (= Ähnlichkeits/Distanzmessung) der Vektoren dazu führt, dass semantisch ähnliche Wörter möglichst nah und Wörter unterschiedlicher Bedeutung weiter auseinander liegen. Doc2Vec erstellt analog dazu einen Vektor für ein ganzes Dokument, sodass anstatt Wörter Dokumente miteinander verglichen werden können. Im vorliegenden Beispiel bedeutet dies, dass jede Betreffzeile in eine Vektorrepräsentation transformiert wird, um anschließend die Betreffszeilen auf Basis ihrer Vektoren auf Ähnlichkeit hin zu überprüfen und mögliche Cluster ähnlicher Betreffzeilen bilden zu können.
In dieser Analyse werden die Dokument-Vektoren von spaCy verwendet (in der mittleren Varianten und 300 Dimensionen), " [... which default] to an average of the token vectors" (spaCy Docs).
umap/HDBSCAN:
Um das eigentliche Clustering durchzuführen, gibt es unterschiedliche Techniken, darunter k-means Clustering, (H)DBSCAN, Hierarchisches Clustering und vieles mehr. Vor dem Clustering wird jedoch zuerst vorbereitend das relativ neue umap Verfahren verwendet, das die vormals hochdimensionalen Vektoren reduziert und somit leichter visualisierbar macht. Die so reduzierten Daten werden dann mit HDBSCAN geclustert und anschließend visualisiert.
4.4.1 Vektorisierung (spaCy)¶
In einem ersten Schritt werden die Betreffzeilen mit spaCy vektorisiert. spaCys Wortvektoren aus den mittleren Modellen (hier: de_core_news_md) haben 300 Dimensionen, sodass jeder Dokumentvektor einer Betreffzeile im folgenden Datensatz ebenfalls eine Dimension von 300 hat.
# loading document vectors (see Code Appendix)
with open("doc_vecs.pkl", "rb") as f:
vecs = pickle.load(f)
# vector of the first subject: "Kehrer über Religion"
vecs.iloc[0]
0 0.648040
1 0.448960
2 -1.376667
3 -0.711435
4 -0.765597
...
295 0.497893
296 0.735443
297 -0.823900
298 -1.129867
299 1.687930
Name: Kehrer ueber Scientology, Length: 300, dtype: float32
# vectors of the first five subjects
vecs.iloc[:5]
| 0 | 1 | ... | 298 | 299 | |
|---|---|---|---|---|---|
| Kehrer ueber Scientology | 0.648040 | 0.448960 | ... | -1.129867 | 1.687930 |
| Korrektion | 1.462600 | 1.247500 | ... | -0.586430 | 1.139300 |
| Tagung England | 2.625885 | 1.048010 | ... | 1.163675 | 2.816000 |
| Adresse Fuer beitraege | 1.907067 | -0.024577 | ... | -0.892833 | 1.223500 |
| virtuell Ausflug | 0.711900 | -1.132605 | ... | -0.471435 | 0.979915 |
5 rows × 300 columns
4.4.2 Clustering (umap und HDBSCAN)¶
Aufgrund der hohen Dimensionalität (300) eignen sich die Dokumentvektoren nur begrenzt für Ähnlichkeits-/Distanzmessungen (curse of dimensionality). Daher wird in einem nächsten Schritt eine Dimensionsreduktion auf die hochdimensionalen Daten angewendet, um diese auf 2 Dimensionen zu reduzieren. Hierfür gibt es Verfahren wie PCA und umap (Uniform Manifold Approximation and Projection). In diesem Beispielprojekt wird umap verwendet.
reducer = umap.UMAP(metric="cosine", n_components=2, random_state=42)
embedding = reducer.fit_transform(vecs)
/mnt/d/environments/ds_lecture_311/lib/python3.11/site-packages/umap/umap_.py:1943: UserWarning: n_jobs value -1 overridden to 1 by setting random_state. Use no seed for parallelism.
warn(f"n_jobs value {self.n_jobs} overridden to 1 by setting random_state. Use no seed for parallelism.")
Die neue Vektorrepräsentation hat jetzt nur noch zwei Dimensionen, was sowohl das Rechnen als auch die Visualisierung deutlich vereinfacht:
embedding[0]
array([ 6.033508, -5.082357], dtype=float32)
Jetzt kann die Verteilung der Betreffzeilen auf Basis ihrer zweidimensionalen Vektoren visualisiert werden, was hoffentlich bereits einen ersten visuellen Eindruck potentieller Cluster ermöglicht.
plot_embeddings(embedding)

In den dimensionsreduzierten Daten wird deutlich, dass es mindestens zwei größere und mehrere kleinere Cluster gibt. Um diese zu identifizieren und zu labeln, wird der Datensatz nun mit HDBSCAN geclustert.
clusterer = hdbscan.HDBSCAN(min_cluster_size=40)
cluster_labels = clusterer.fit_predict(embedding)
vecs_labels = vecs.copy()
vecs_labels["cluster"] = cluster_labels
plot_cluster(embedding, cluster_labels)

vecs_labels.value_counts("cluster")
cluster 4 2795 15 2703 -1 700 11 349 14 326 8 171 12 147 3 105 0 96 9 89 10 86 6 52 1 47 13 46 5 45 2 43 7 43 Name: count, dtype: int64
HDBSCAN konnte mit den gewählten Argumenten 16 Cluster identifizieren. Aber sind die Cluster überhaupt aussagekräftig? Cluster -1 enthält immer Datenpunkte, die keinem Cluster zugewiesen werden konnten (noise). Diese Datenpunkte können entsprechend für das Clustering ignoriert werden. Cluster 4 und 15 enthalten sehr viele Datenpunkte und sind daher ebenfalls nur wenig brauchbar. Bei den anderen Clustern, die jeweils um die 71-300 Betreffzeilen enthalten, sieht es schon anders aus, und es können hier in der Tat einige Gemeinsamkeiten bzw. Strukturen erkannt werden.
Das folgende Cluster enthält beispielsweise Betreffzeilen zu Konferenzen, vor allem der EASR:
vecs_labels[vecs_labels.cluster == 3]["cluster"][:25]
Iahr Congress Durban 3 Mircea eliaden 3 conference Detail 3 Cambridge conference Programm 3 Easr Cambridge conference Programm 3 Easr conference Documents 3 Haeuptling Seattle 3 conference 3 Easr conference 3 Programm 3 Conference Paris update 3 Iahr Conference Delhi 3 Vacancy Amsterdam 3 Paris bergen 3 charming conference 3 Shinto wars 3 Delhi 3 Easr congress Congrès 3 Easr Conference Bergen 3 Easr congress Programm 3 Easr congress Deadline 3 Iahr Weltkongress Tokyo 3 Tokyo 3 Iahr Conference Indonesia 3 Sseasr conference 3 Name: cluster, dtype: int64
Cluster 13 beinhaltet Betreffzeilen, die mit "Religionswissenschaft" (sowie anderen Universitätsfächern) in Verbindung stehen.
vecs_labels[vecs_labels.cluster == 13]["cluster"][:25]
polylzentrisch Religionswissenschaft 13 Religionswissenschaft 13 Sekt angewandt Religionswissenschaft 13 Religionswissenschaft Magisternebenfach fwd 13 infoheft Religionswissenschaft religionsgeschichte 13 infoheft Religionswissenschaft 13 angewandt Religionswissenschaft Kopftuchurteil 13 angewandt Religionswissenschaft 13 studierendenzahlen Religionswissenschaft zuwachsraten 13 praktisch Religionswissenschaft 13 Verhältnis Religionswissenschaft Religionspädagogik 13 Positionspapier Missionswissenschaft Religionswissenschaft 13 Kopftuchurteil angewandte Religionswissenschaft 13 Doktorandenstelle Religionswissenschaft 13 Wallraff Religionswissenschaft 13 Lektorenstelle Religionswissenschaft 13 Studierendensymposium Religionswissenschaft 13 Religionswissenschaft wikipedia 13 Sozialwissenschaft 13 mitarbeiterstell Religionssoziologie 13 Lectureship Islamwissenschaften 13 studieneingangstests Religionswissenschaft 13 Wikipedia Religionswissenschaft 13 wiki Religionswissenschaft 13 Doktorandenstipendi Religionswissenschaft Islamwissenschaft 13 Name: cluster, dtype: int64
Die gefundenen Cluster können nun im weiteren Verlauf der Analyse untersucht werden, zum Beispiel mit Methoden aus dem Bereich der qualitativen Forschung. Da es sich lediglich um ein Beispielprojekt handelt, wird die Clustering-Analyse an dieser Stelle beendet, da hoffentlich gezeigt werden konnte, wozu diese potenziell in der Lage ist.
5. Zusammenfassung¶
Ich hoffe, dass ich in dieser Sitzung zeigen konnte, (1) aus welchen Teilschritten ein typisches Data Science Vorhaben besteht (2) und wie die einzelnen Teile in einem konkreten Projekt unter einer geisteswissenschaftlichen Fragestellung zusammengeführt werden können. Die dafür erforderlichen Daten lassen sich an vielen Stellen finden und oft wird man erst auf sie aufmerksam, wenn entsprechende Fähigkeiten erworben wurden und man mit einer "Datenbrille" durch die Welt läuft.
Zum Abschluss soll noch einmal daran erinnert werden, dass für die jeweiligen Schritten nicht unbedingt die Kenntnis einer Programmiersprache erforderlich, auch wenn diese die Arbeit maßgeblich vereinfachen kann.
6. Literatur¶
Alby, Tom. 2022. Data Science in der Praxis: eine verständliche Einführung in alle wichtigen Verfahren. 1. Auflage. Rheinwerk computing. Bonn: Rheinwerk Verlag.
Biemann, Chris, Gerhard Heyer, und Uwe Quasthoff. 2022. Wissensrohstoff Text: eine Einführung in das Text Mining. 2., Wesentlich überarbeitete Auflage. Wiesbaden: Springer Vieweg.
Holmes, Dawn E. 2017. Big data: a very short introduction. First edition. Very short introductions 539. Oxford, United Kingdom: Oxford University Press.
Kane, Megan S. 2023. „Corpus Analysis with spaCy“. Herausgegeben von John R. Ladd. Programming Historian, Nr. 12 (November). https://doi.org/10.46430/phen0113.
Kelleher, John D., und Brendan Tierney. 2018. Data science. The MIT Press essential knowledge series. Cambridge, Massachusetts: The MIT Press.
Reades, Jonathan, und Jennie Williams. 2023. „Clustering and Visualising Documents Using Word Embeddings“. Herausgegeben von Alex Wermer-Colan. Programming Historian, Nr. 12 (August). https://doi.org/10.46430/phen0111.
7. Code Appendix¶
# imports
import pickle
import email
import re
from typing import List, Dict
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from collections import Counter
import pandas as pd
import spacy
from langdetect import detect
import umap
import umap.plot
import hdbscan
# pandas options
pd.set_option('display.max_colwidth', None)
# sns options
sns.set_style("whitegrid") # Set the background style
sns.set_palette("viridis") # Set the color palette
# spacy
nlp = spacy.load("de_core_news_md")
/mnt/d/environments/ds_lecture_311/lib/python3.11/site-packages/umap/plot.py:203: NumbaDeprecationWarning: The keyword argument 'nopython=False' was supplied. From Numba 0.59.0 the default is being changed to True and use of 'nopython=False' will raise a warning as the argument will have no effect. See https://numba.readthedocs.io/en/stable/reference/deprecation.html#deprecation-of-object-mode-fall-back-behaviour-when-using-jit for details. @numba.jit(nopython=False)
6.1 Cleaning/Transformation¶
with open("../Datasets/Yggdrasill_1997-2023/storage_all.pkl", "rb") as f:
data = pickle.load(f)
### HELPER FUNCTION FOR get_subject_from_emails()
def clean_subject(subject: str) -> str:
'''Function to clean an email-subject using RE.
'''
CLEANING_PATTERN = re.compile(r"^re:\s+\[ygg\]|^fwd:\s+\[ygg\]|^aw:\s+\[ygg\]|^re:\s+fwd:\s+\[ygg\]|^\[ygg\]|\baw:|\bfwd:|\bfw:|\bre:|\[dolmen\]|\[candide\]|\[ygg\]", re.IGNORECASE)
subject = re.sub(CLEANING_PATTERN, " ", subject)
subject = re.sub(r"\s{2,}", " ", subject)
subject = subject.strip().lower()
return subject
def get_subject_from_emails(email_dict: Dict[int, Dict[str, Dict[int, email.message.Message]]]) -> Dict:
'''Extract SUBJECT field from emails retrieved via get_emails_from_folder().
Parameters
----------
email_dict: Dict[str, Dict[str, Dict[int, email.message.Message]]
The dictionary with emails, retrieved using get_emails_from_folder().
Returns
-------
(Dict)
{
<YEAR: int>: List[str]
}
'''
emails = dict()
for year in email_dict:
emails[year] = list()
for month in email_dict[year]:
for idx, mail in email_dict[year][month].items():
subject = mail["subject"]
if subject != None:
emails[year].append(clean_subject(subject))
return emails
subject_dictionary = get_subject_from_emails(data)
with open("subjects_1997-2023_clean.pkl", "wb") as f:
pickle.dump(subject_dictionary,f)
6.2 EDA¶
6.2.1 Beiträge/Jahr Plot¶
# get years/messages from subjects dictionary
years = [str(k) for k,_ in subjects_dict.items()]
messages = [len(v) for _,v in subjects_dict.items()]
def visualize_messages_per_year(years: List[str], messages: List[int]) -> None:
'''Function to visualize messages distro per year with matplotlib.'''
sns.lineplot(x=years, y=messages, marker='o', markersize=8, linestyle='-', linewidth=2)
plt.title(f"Yggdrasill Beiträge/Jahr 1997-2023", fontsize=16)
plt.xlabel("Jahr", fontsize=13)
plt.xticks(rotation=45)
plt.ylabel("Anz. Beiträge", fontsize=13)
plt.ylim(0, max(messages)+200)
plt.tight_layout()
plt.savefig(f"yearly_stats.png")
visualize_messages_per_year(years, messages)

6.2.2 Statistische Kennzahlen¶
## arithm. Mittel
np.sum(messages)/len(years)
545.9629629629629
## Median
np.median(messages)
497.0
6.2.3 Boxplot / Violinplot¶
subject_len_dict = {year: [len(betreff) for betreff in messages] for year,messages in subject_dictionary.items()}
all_subject_len = list()
for _,v in subject_len_dict.items():
all_subject_len.extend(v)
def create_boxplot(msg_len_list: List[int]) -> None:
'''Function to visualize the distribution of Betreffzeilen-length using a boxplot.'''
plt.figure(figsize=(8, 6))
sns.boxplot(x=msg_len_list, color='skyblue')
# labels and a title
plt.ylabel("Beiträge", fontsize=14)
plt.xlabel("Länge", fontsize=14)
plt.title("Boxplot: Länge der Betreffzeilen", fontsize=16)
plt.tight_layout()
plt.savefig("boxplot.png")
def create_violinplot(msg_len_list: List[int]) -> None:
'''Function to visualize the distribution of Betreffzeilen-length using a violin-plot.'''
plt.figure(figsize=(8, 6))
sns.violinplot(x=msg_len_list, color='orchid')
# labels and a title
plt.ylabel("Beiträge", fontsize=14)
plt.xlabel("Länge", fontsize=14)
plt.title("Violinplot: Länge der Betreffzeilen", fontsize=16)
plt.tight_layout()
plt.savefig("violinplot.png")
create_boxplot(all_subject_len)

create_violinplot(all_subject_len)

6.2.4 Filter Betreff¶
def filter_subjects_by_length(subjects: List[str], min_len: int) -> np.array:
'''Function to filter list of subjects to keep only subjects of a certain lengths.'''
np_subjects = np.array(subjects)
boolean_subjects = np.array([len(subject) > min_len for subject in np_subjects])
return np_subjects[boolean_subjects]
#filter_subjects_by_length(all_subjects, 150)
6.4 Analyse¶
6.4.1 Häufigste Themen¶
def show_most_frequent_topics(messages: List[str], topics=10):
'''Function to show list of top subjects.'''
cnt = Counter(messages)
df = pd.DataFrame(list(cnt.items()), columns=['Betreff', 'Anzahl'])
return df.sort_values("Anzahl", ascending=False).iloc[:topics].reset_index().drop(columns=["index"])
#show_most_frequent_topics(all_subjects)
6.4.2 Lemmatisierung¶
def lemmatize_subject(subject: str) -> str:
'''Function to lemmatize a text string using spaCy.'''
text = nlp(subject)
lemmatized_text = " ".join([word.lemma_ for word in text if not word.is_stop and word.is_alpha])
return lemmatized_text
# erstellung lemmatisierte subjects
all_subjects_lemmatized = [lemmatize_subject(sub) for sub in all_subjects]
with open("subjects_lemmatized.pkl", "wb") as f:
pickle.dump(all_subjects_lemmatized,f)
6.4.3 Themen/Jahr¶
def plot_topics_per_year(subject_year_dict: Dict[int,List[str]], search_terms: List[str]) -> None:
'''Function to plot how often the terms/topic are mentioned each year + list of top topics.'''
topic_year_dict = dict()
topics = list()
for year,subjects in subject_year_dict.items():
topic_year_dict[year] = 0
for subject in subjects:
for kw in search_terms:
if kw in subject:
topic_year_dict[year] += 1
#print(subject) # DEBUG
topics.append(subject)
break
# plotting
years = [str(y) for y in topic_year_dict.keys()]
sns.lineplot(x=years, y=topic_year_dict.values(), marker='o', markersize=8, linestyle='-', linewidth=2)
plt.title(f"Yggdrasill Beiträge/Jahr 1997-2023 mit Themen: {', '.join(search_terms)}", fontsize=16)
plt.xlabel("Jahr", fontsize=13)
plt.xticks(rotation=45)
plt.ylabel("Anz. Beiträge", fontsize=13)
plt.ylim(-10, max(topic_year_dict.values())+10)
plt.tight_layout()
plt.show()
# show most frequent topics
cnt = Counter(topics)
print(cnt.most_common(5))
6.4.4 BoW¶
def bow(subjects: List[str], top=10) -> Counter:
'''Function to create a bag-of-words from list of texts.'''
cnt = Counter()
for sub in subjects:
cnt.update(sub.split())
# check if words are really german
counter = 0
top_words = dict()
for word,count in cnt.most_common():
try:
lang = detect(word)
except:
lang = "fail"
if lang == "de":
top_words[word] = count
counter += 1
if counter == top:
break
return top_words
6.4.5 Clustering¶
def doc2vec(subjects_list: List[str]) -> pd.DataFrame:
'''Function to create subject vectors for each subject line with spaCy.'''
vec_dict = dict()
for subject in subjects_list:
doc = nlp(subject)
if doc.has_vector:
vec_dict[subject] = doc.vector
df = pd.DataFrame.from_dict(vec_dict, orient="index")
return df
vecs = doc2vec(lemmatized_subjects)
with open("doc_vecs.pkl", "wb") as f:
pickle.dump(vecs, f)
with open("doc_vecs.pkl", "rb") as f:
vecs = pickle.load(f)
#vecs
def plot_embeddings(embeddings: np.array) -> None:
'''Function to plot embeddings from umap.'''
plt.scatter(embeddings[:, 0], embeddings[:, 1], s=5)
plt.title('UMAP Embeddings (Yggdrasill Analysis)')
plt.show()
def plot_cluster(embeddings: np.array, labels: List[str]) -> None:
'''Function to plot embeddings from umap.'''
plt.scatter(embeddings[:, 0], embeddings[:, 1], c=labels, cmap='Spectral', s=5)
plt.colorbar()
plt.title('HDBSCAN Clustering on UMAP Embeddings (Yggdrasill Analysis)')
plt.show()